ICGAN
AN IMPLICIT CONDITIONING METHOD FOR INTERPRETABLE FEATURE CONTROL OF NEURAL AUDIO SYNTHESIS
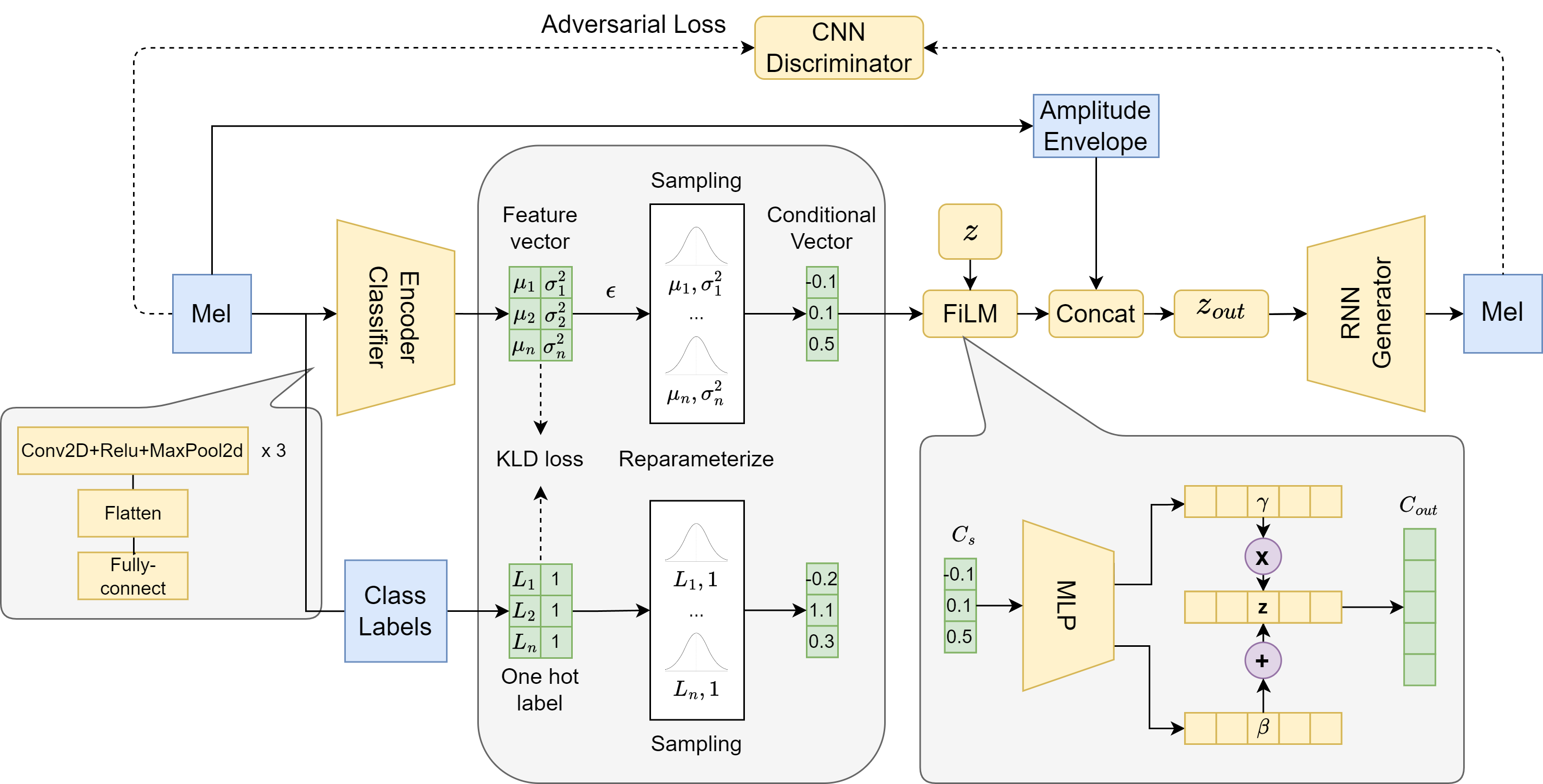
ICGAN architecture
Abstract
Neural audio synthesis methods can achieve high-fidelity and realistic sound generation by utilizing deep generative models. However, such models typically fail to provide convenient or interpretable controls to guide the sound generation, especially with regard to sounds that are hard to describe by words. We propose an implicit conditioning method to achieve smooth interpolation between different classes of sounds with discrete labels. As shown in our architecture, our generator is conditioned on a vector sampled from a Gaussian distribution with mean and variance parameterized from the encoder. The encoder learns the categorical information from the input Mel spectrograms and guides the generator in an implicit way. Our technique creates a continuous conditioning space that enables timbre manipulation without relying on explicit labels. We further introduce an evaluation metric to explore controllability and demonstrate that our approach is effective in enabling a degree of controlled variation of different sound effects for same-class and cross-class sounds.
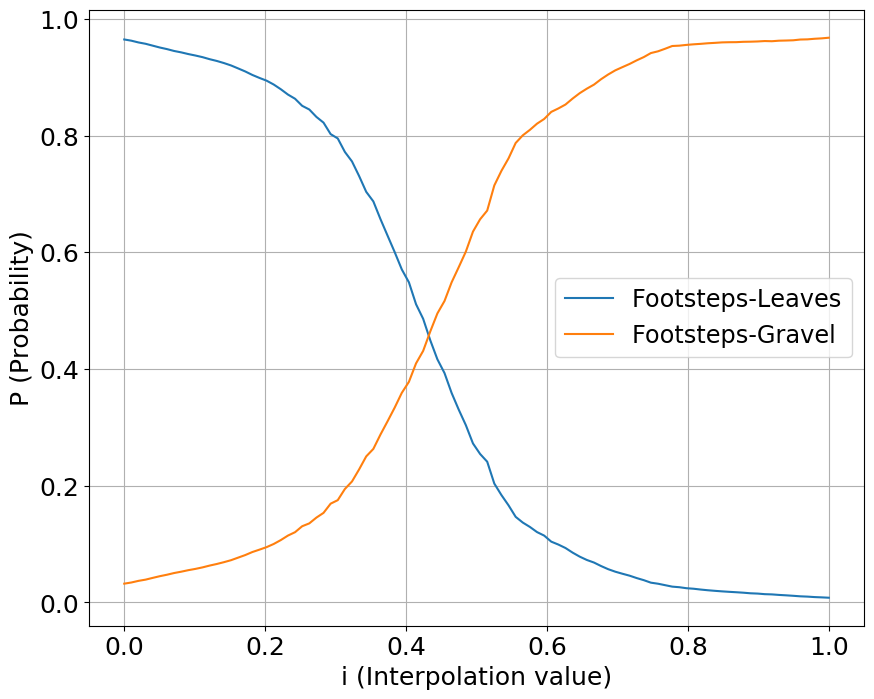
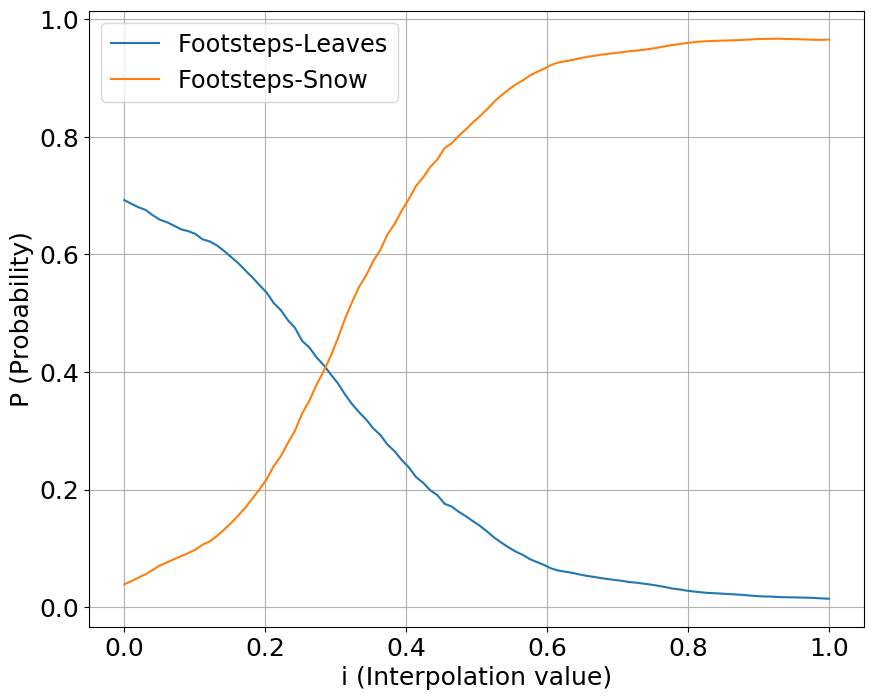
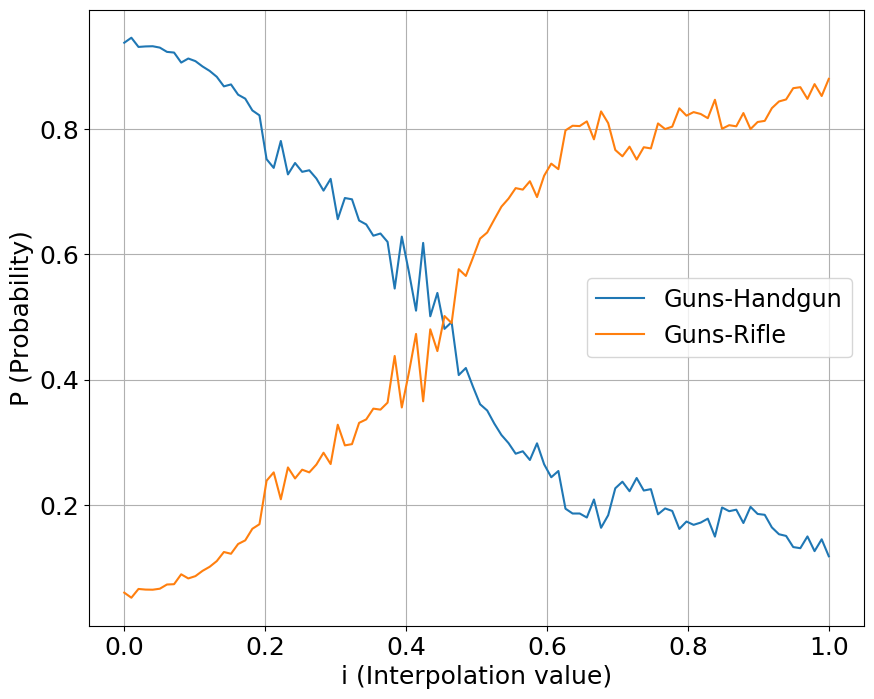
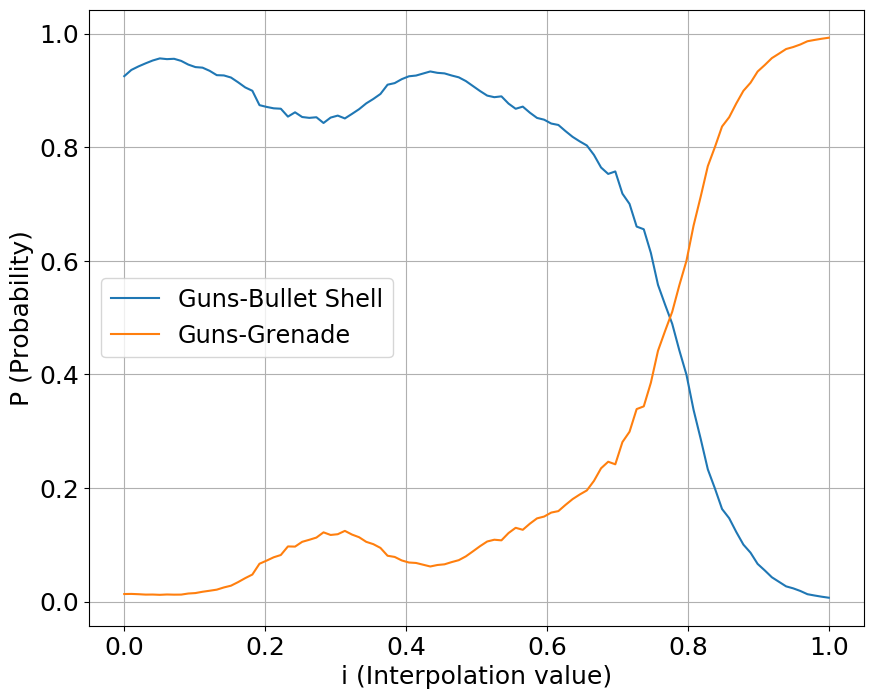
Interpolation
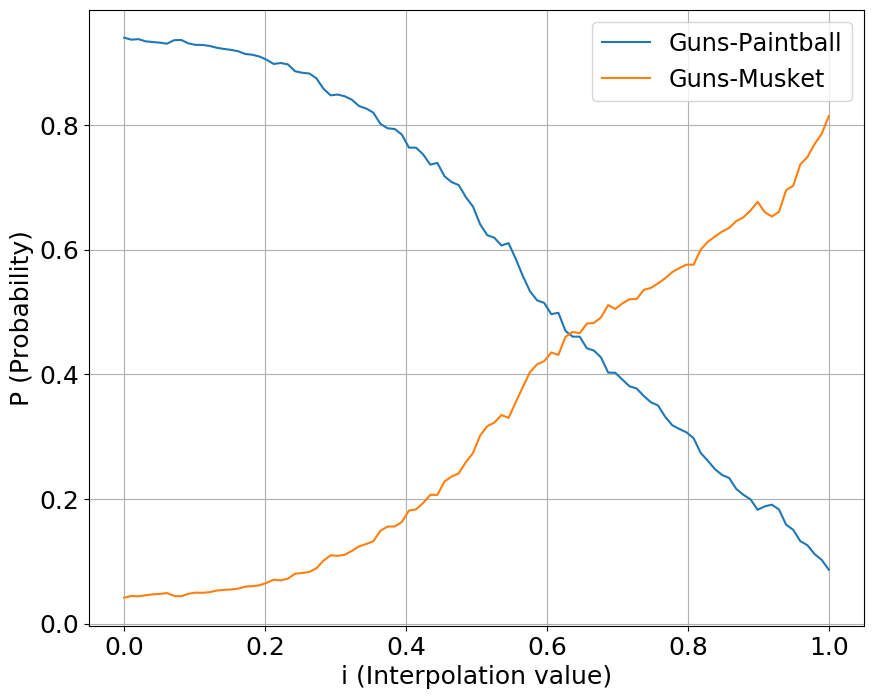
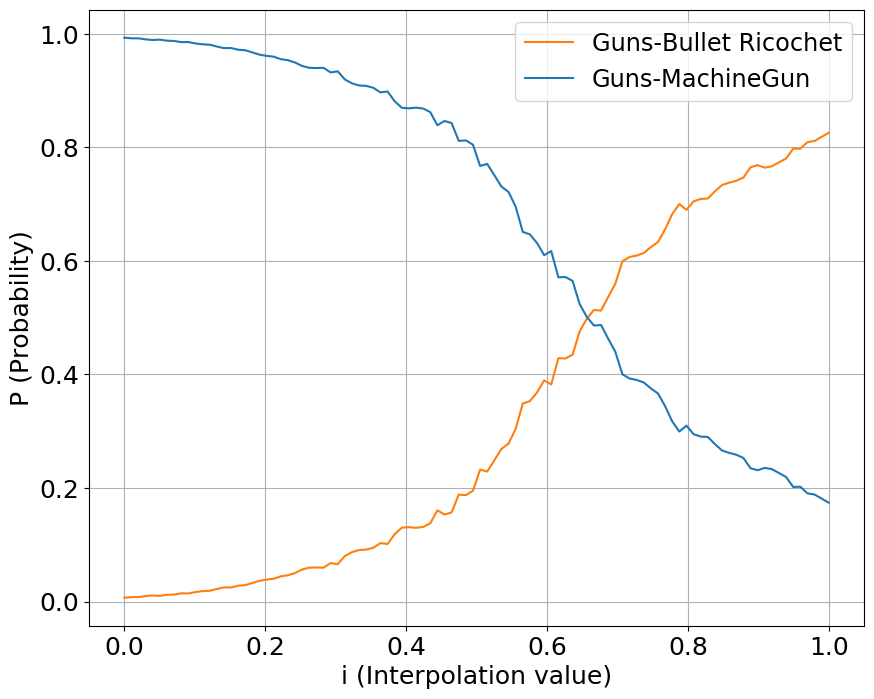
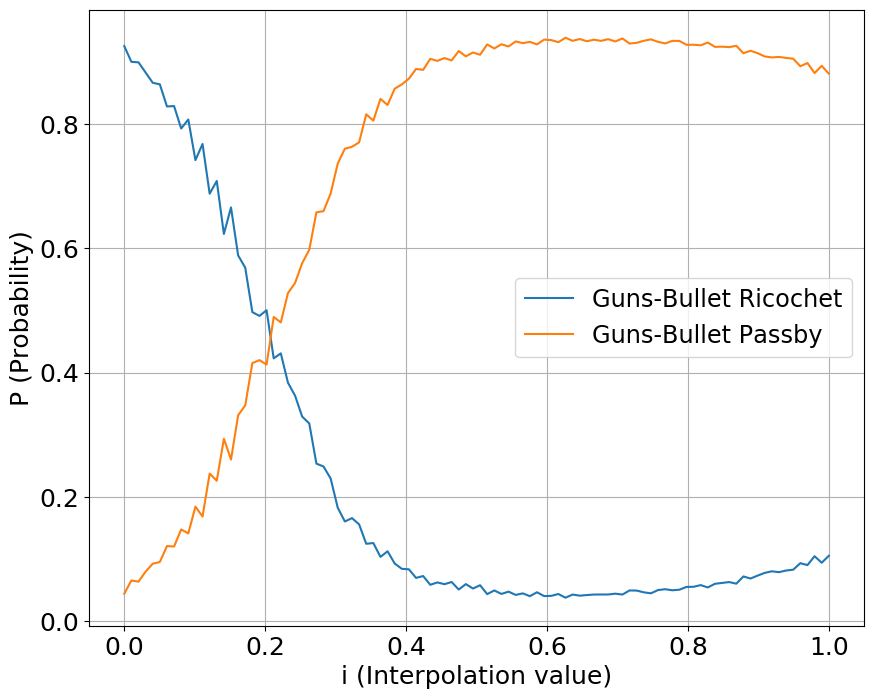
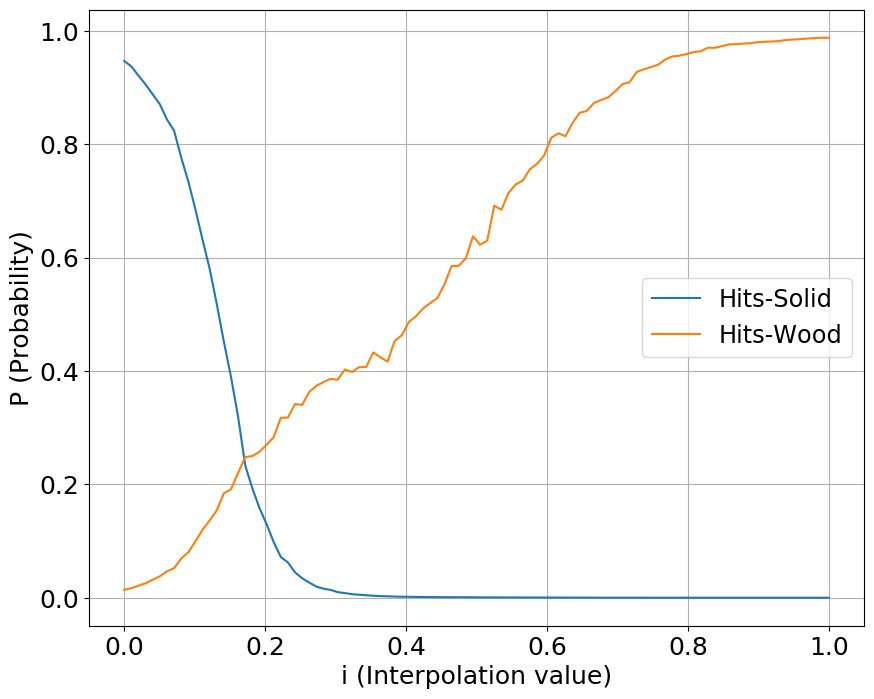
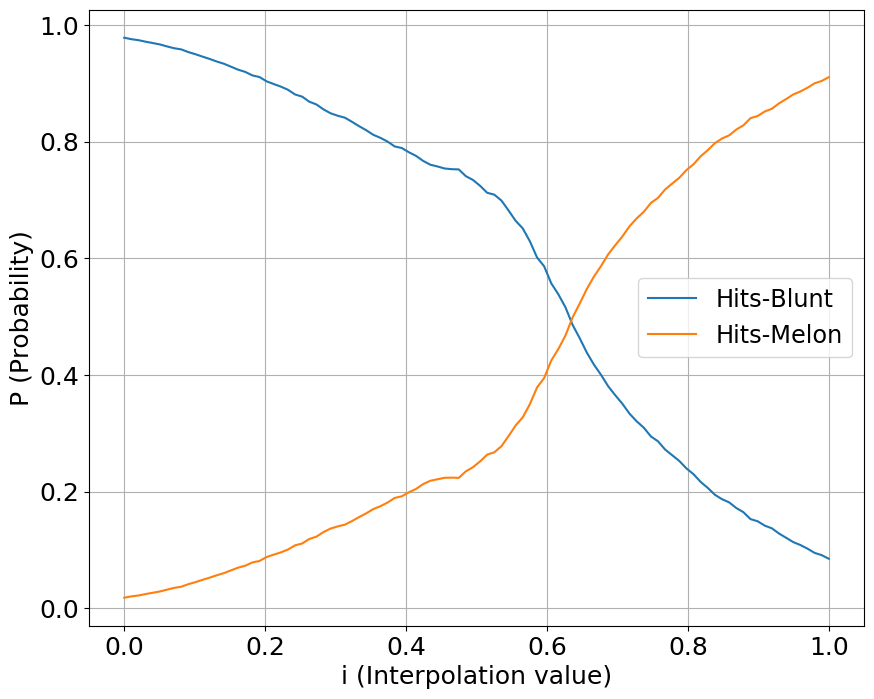
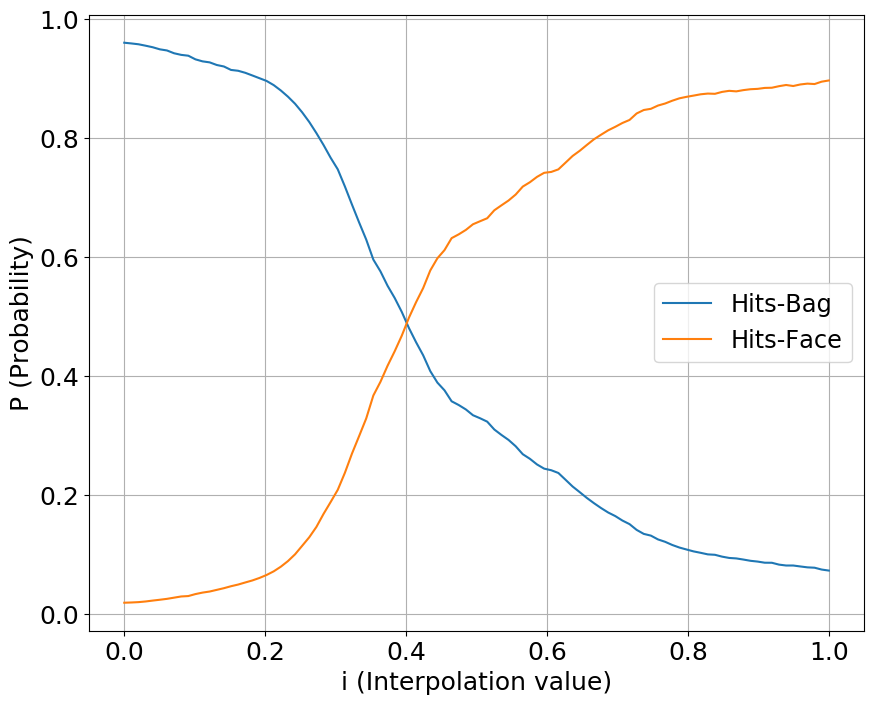
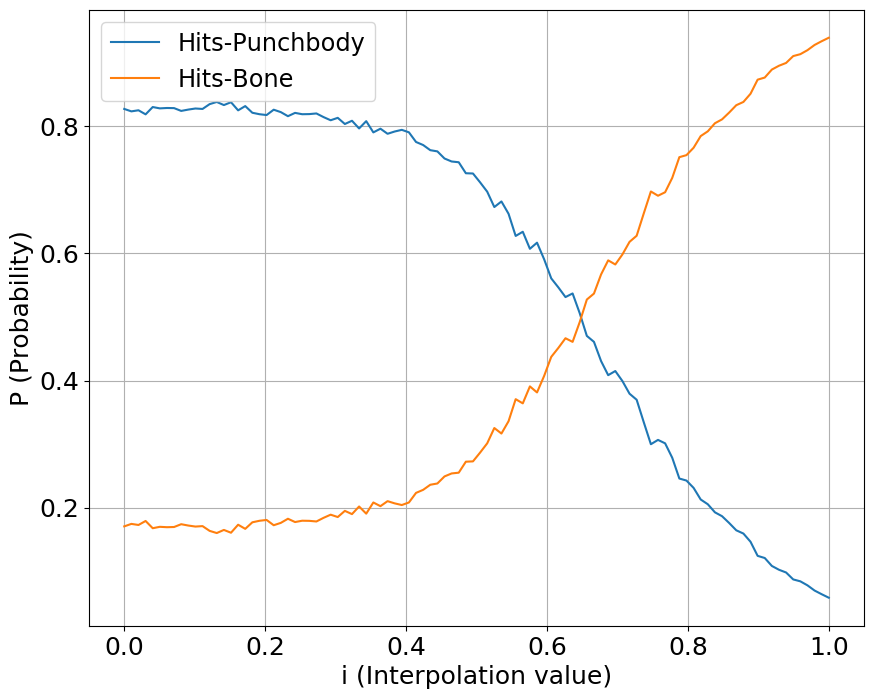
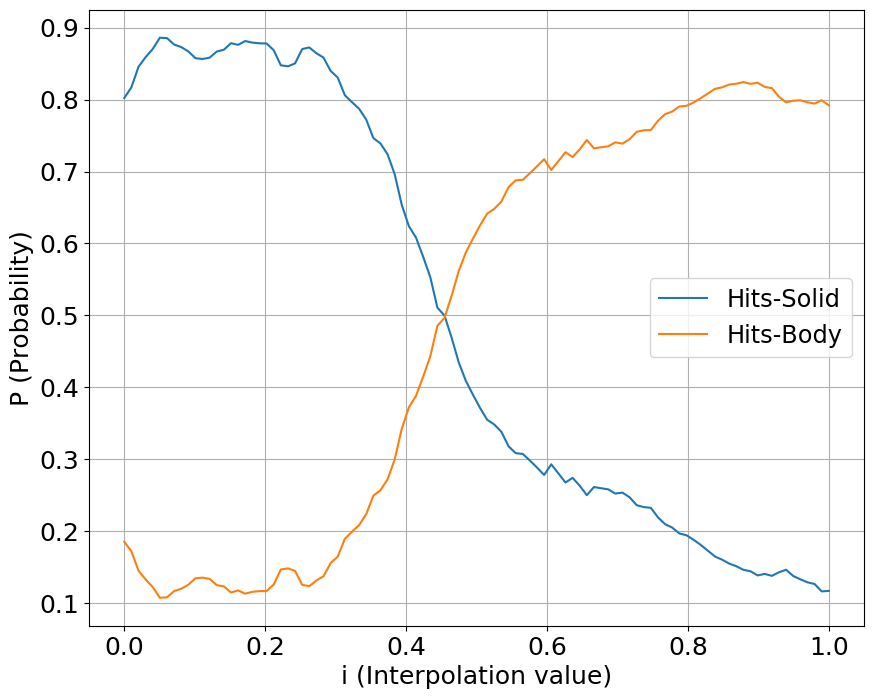
We interpolate our conditioning space between two classes of sounds, one starting a value at 0 while another starting at 1. We show the output probabilities returned from the fine-tuned PANNs classifier.
Footsteps
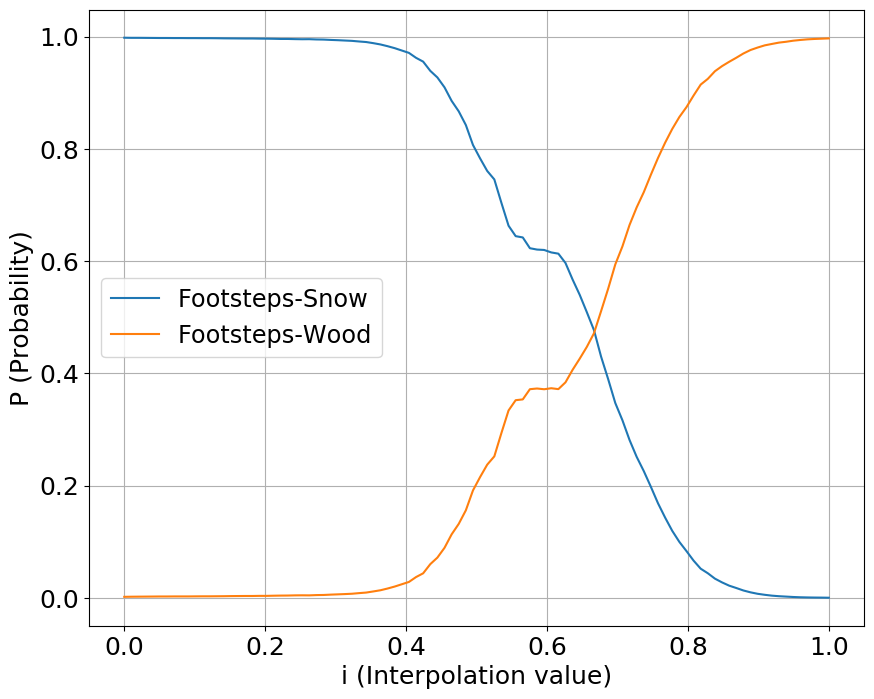
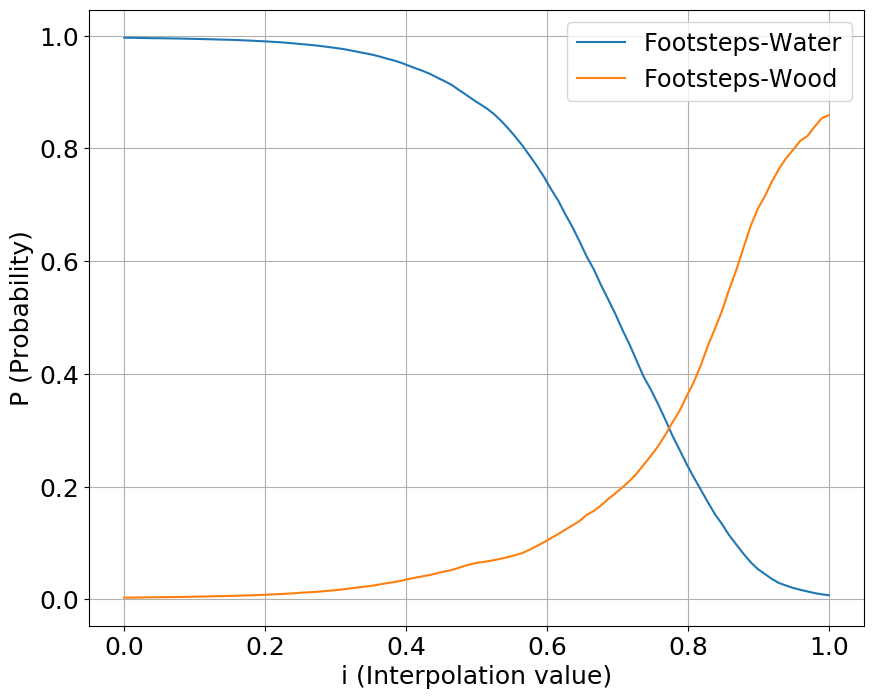
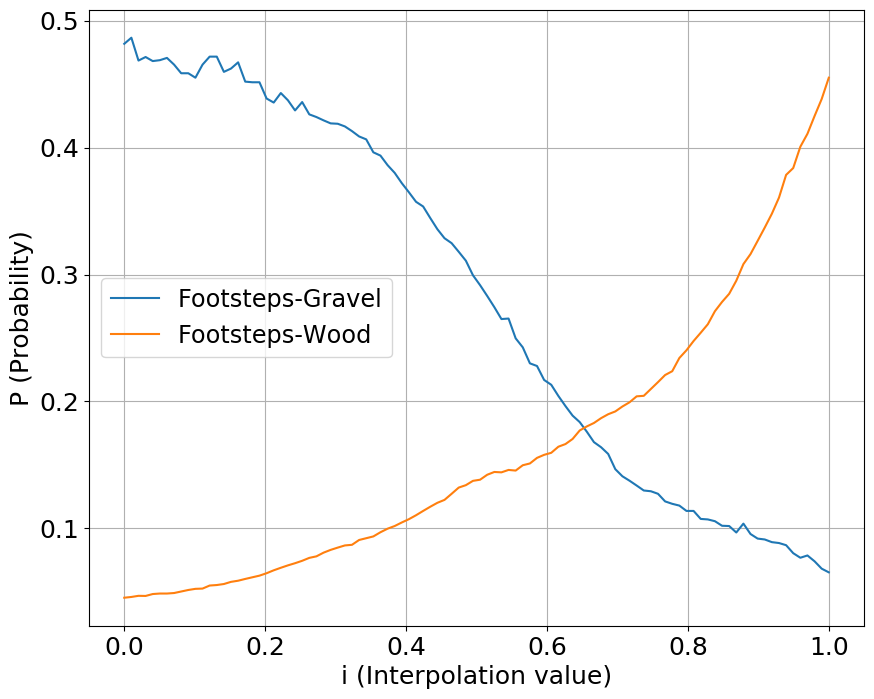
Guns
Hits
Generated sounds with implicit conditioning
During the inference stage, we could generate Mel spectrograms by inputting self-defined sampled vectors. As the learned sampled vectors are expected to have a mean of 0 when the associated class feature is absent and a mean of 1 when the associated class feature is present, we manually set the sampled vectors with 1 at a class dimension and 0 for everywhere else. Below we show the generated Mel spectrograms and transformed sounds conditioned on self-defined vectors.
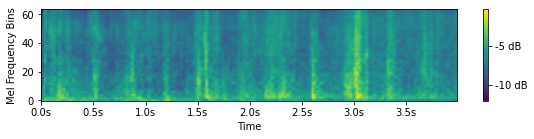
Footsteps
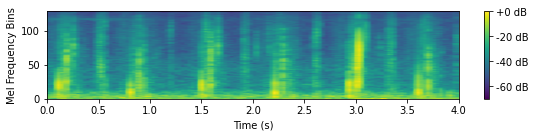
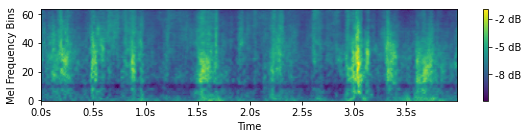
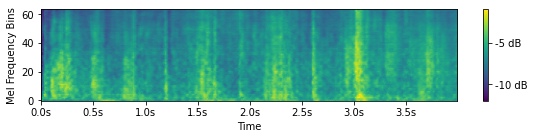
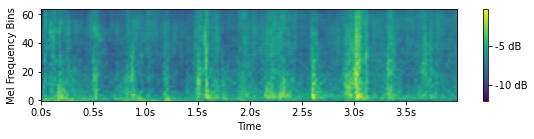
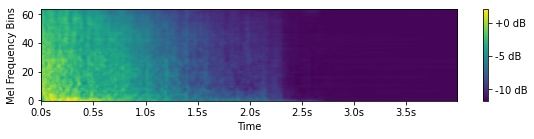
Guns


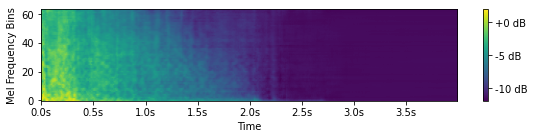

Hits





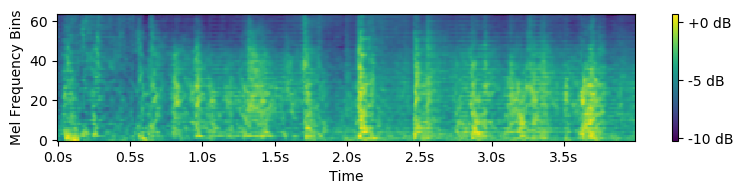
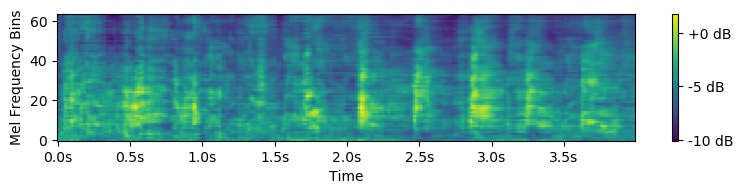
Out-of-class sounds
We also show the generated out-of-class sounds. We also use a reference track for guiding the amplitude envelope. The sounds were generated by inputting required sampled vector corresponding to each class.
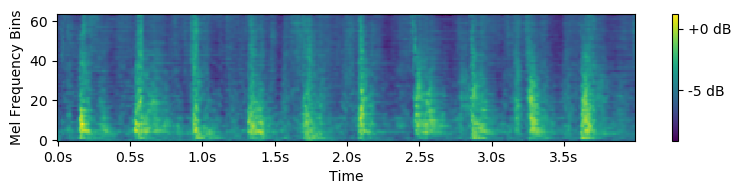
BibTeX
@inproceedings{liu2024icgan,
title={ICGAN: An implicit conditioning method for interpretable feature control of neural audio synthesis},
Conference={Digital Audio Effects Conference 2024},
year={2024},
Pages={73-80},
}